GPI-2 aims at high performance. That includes maximum performance on micro-benchmarks as well as on different kinds of applications. Some of the results and applications based on GPI-2 are depicted below (use the tabs to navigate).
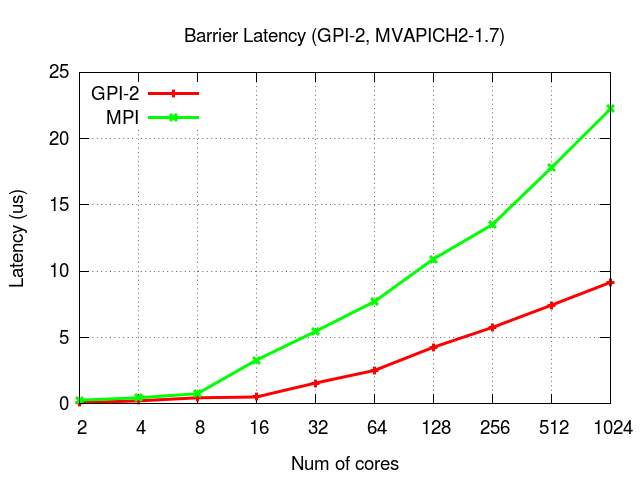
Micro-benchmarks
The presented results were obtained on a system equipped with Infiniband (FDR).
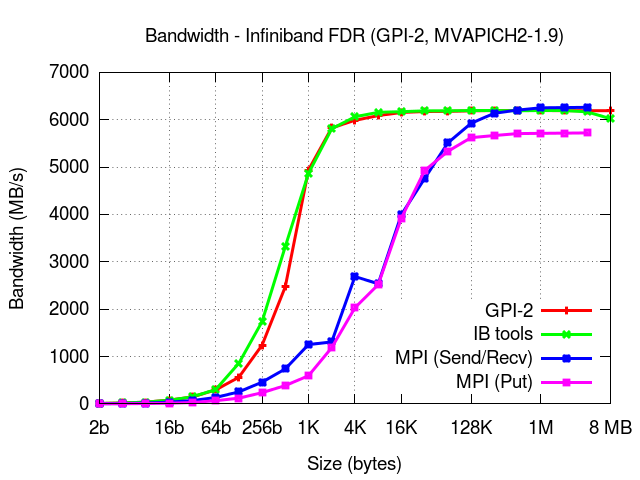
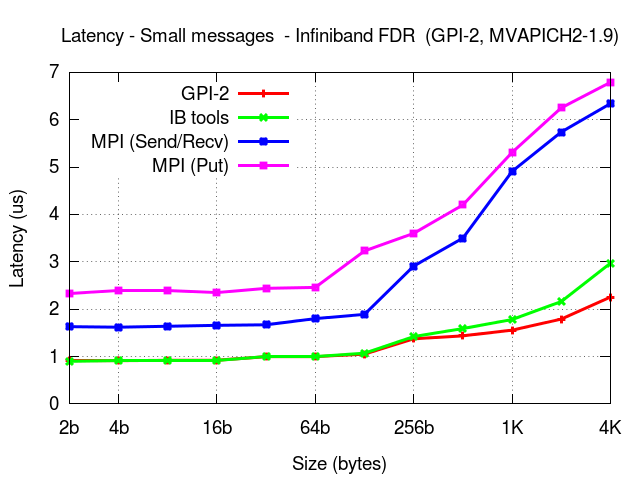
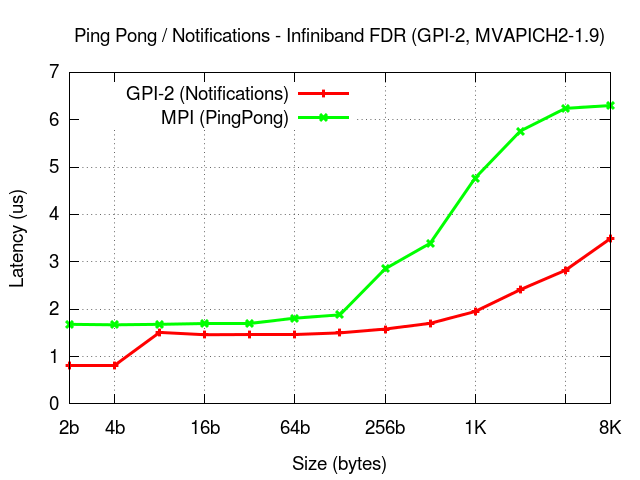

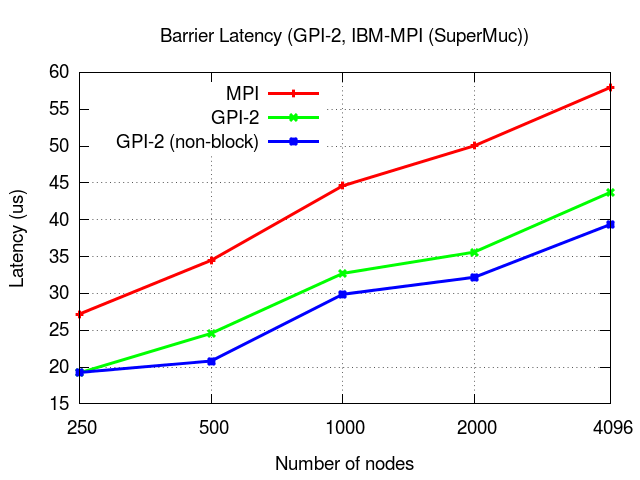
Xeon Phi
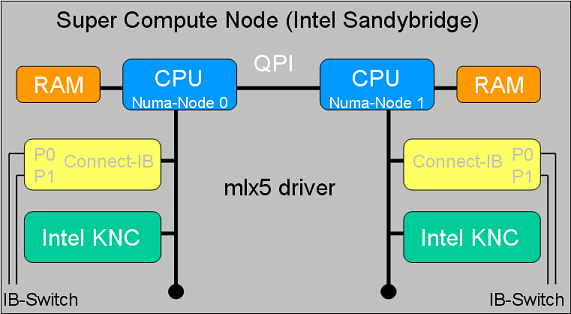
The results below show the performance of GPI2 on heterogeneous architectures namely, on a system with the latest Connect-IB from Mellanox where each (Super compute)node is equipped with 2 IB cards (dual port with port and device bonding enabled) and 2 Intel Xeon Phi, as depicted in the figure below:
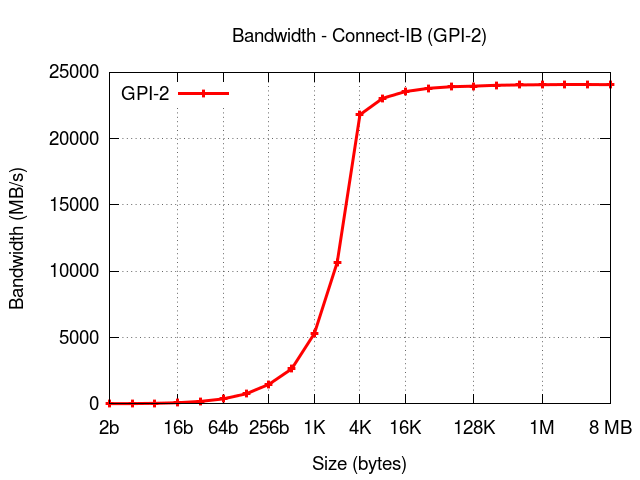
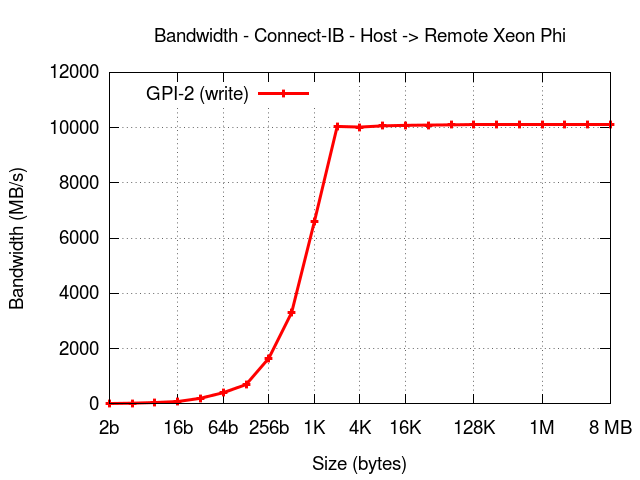
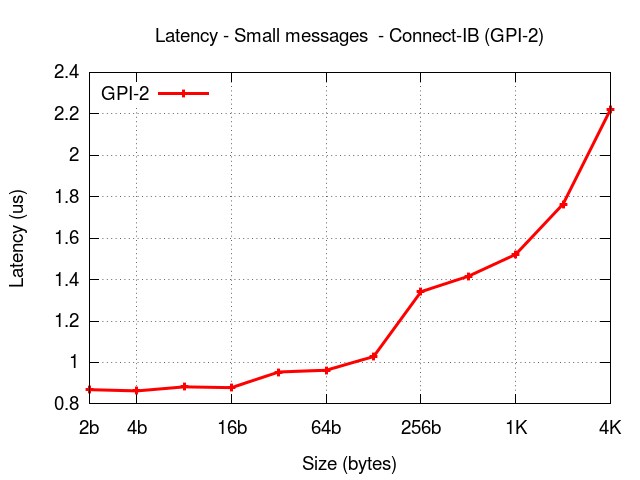
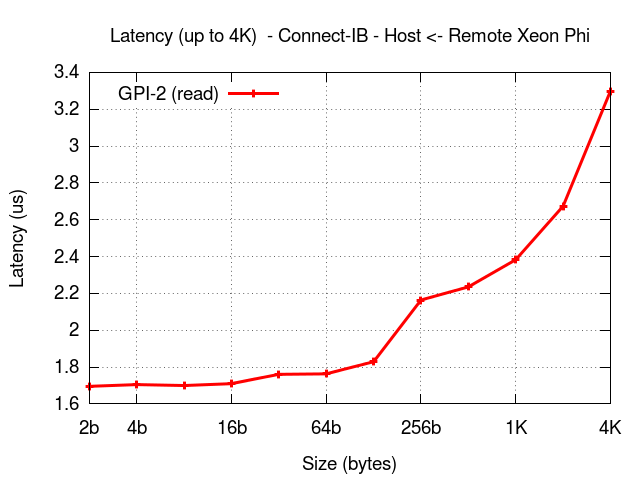
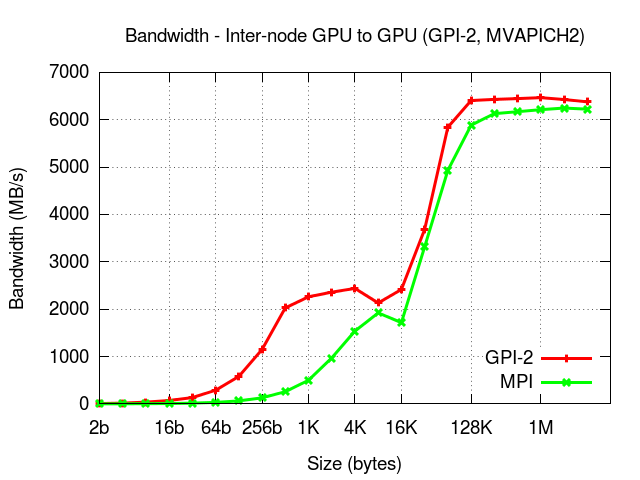
GPU
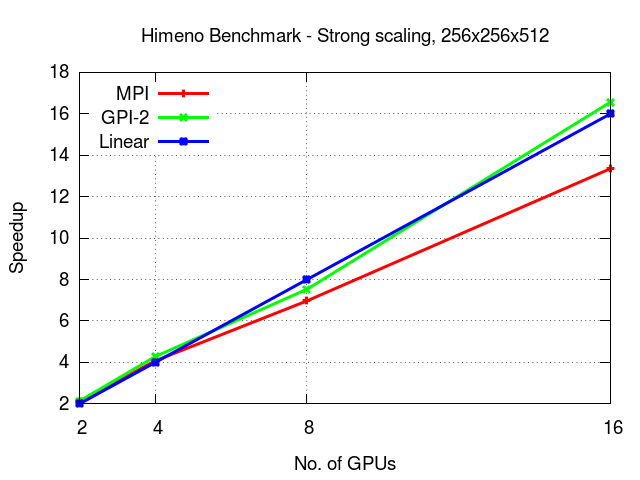
The following figure depicts the obtained speedup when running the Himeno benchmark on a multi-GPU setup and compares it with the speedup obtained when using MVAPICH2 with GPUDirect RDMA enabled.
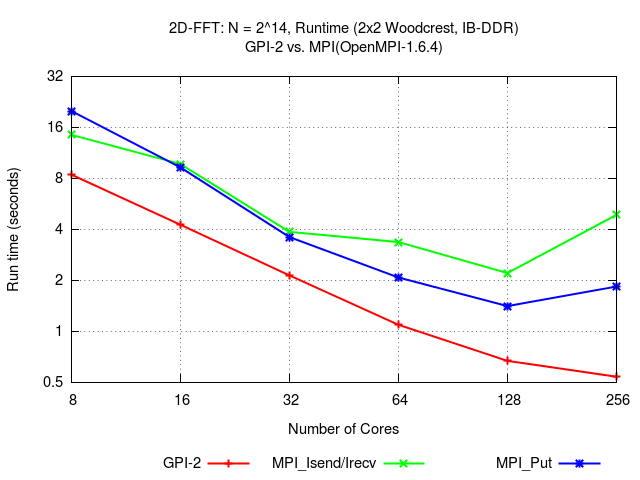
2D-FFT
To illustrate the benefit of computation-communication overlap with GPI-2, the figure below depicts the communication pattern of a 2D-FFT and the required run time (in seconds) on a system with up to 256 cores equipped with Infiniband DDR.
UTS
The Unbalanced Tree Search (UTS) benchmark is a parallel benchmark that examines the performance achieved when performing an exhaustive search on an unbalanced tree. It presents significant load imbalance problems to any parallelization scheme. Below we present the performance results obtained with GPI(*) for one type of tree (binomial) of around 300 billion nodes. View related publication.
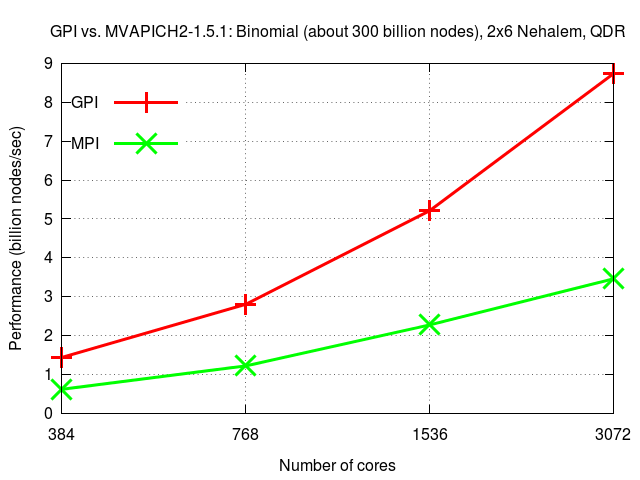
(*) The depicted results were obtained with the previous version of GPI. With GPI-2 the same results are expected.
BQCD
Quantum Chromo Dynamics (QCD) is the fundamental theory of the strong interaction. BQCD is a typical representative of its ab-initio simulation, a boundary exchange problem. The figure below presents the results obtained in terms of overlap of computation and communication efficiency, for a 24×24×24×48 lattice. The system used consists of dual socket Intel Xeon E5440 CPUs running at 2.83 GHz, each having 16 GByte of RAM connected with DDR Infiniband. View related publication.
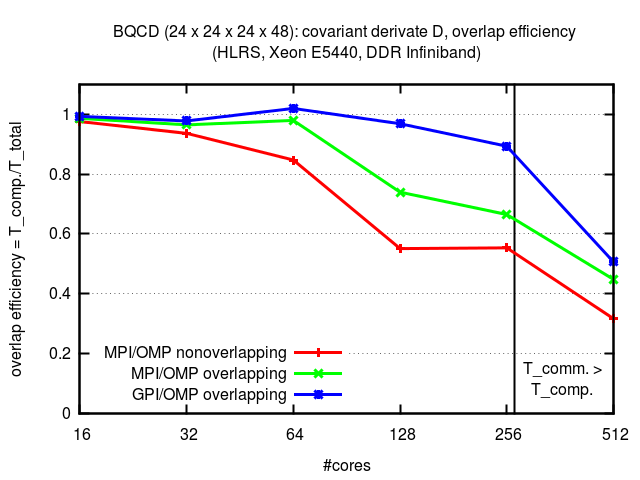
(*) The depicted results were obtained with the previous version of GPI. With GPI-2 the same results are expected.
3D Stencil
The following figure presents the obtained results on the parallelization of a 3D acoustic wave equation kernel from a bulk-synchronous MPI legacy code to asynchronous MPI and GPI. It is also a great representative of stencil computations. It uses OpenMP within the NUMA sockets and the results were obtained on a system with Intel Xeon X5660 (Westmere) and QDR Infiniband. The MPI implementation was Intel MPI 4.0.3. This work was in collaboration with Mauricio Araya-Polo and Repsol.
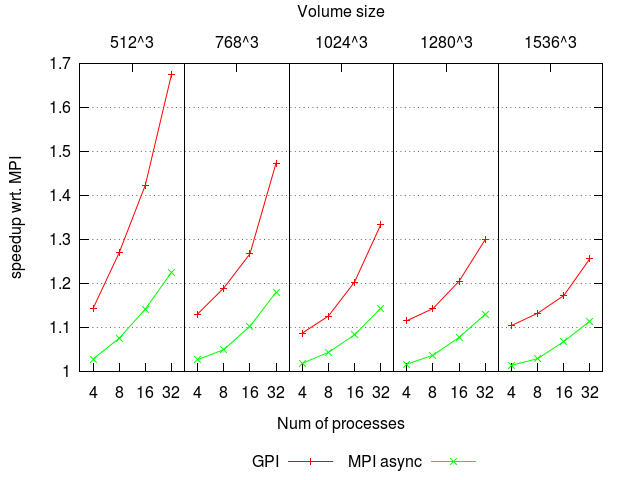
CFD
TAU is an unstructured CFD solver developer by the German Aerospace Center (DLR). The figure below presents the obtained speedup for 4W Multigrid with 2 million mesh points on up to 1440 cores. The system used was equipped with the Intel Xen X5670 and QDR Infiniband. View related publication.
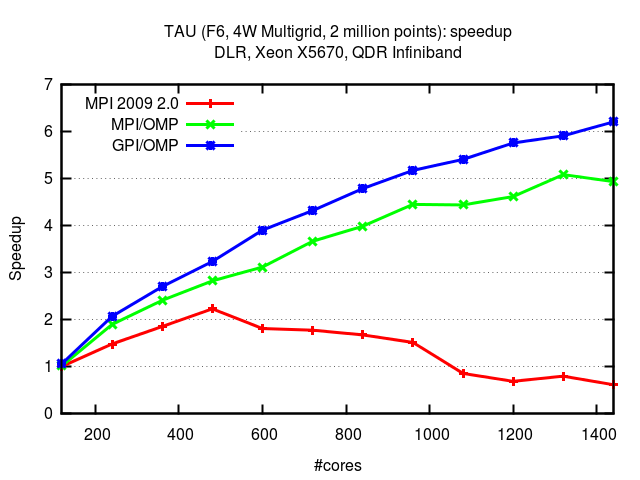
(*) The depicted results were obtained with the previous version of GPI. With GPI-2 the same results are expected.
Numerics
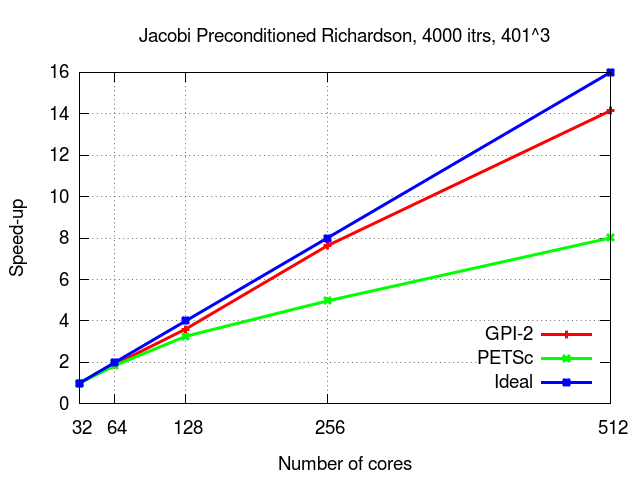
Here we present the results of our GPI-2 implementation of the Jacobi preconditioned Richardson method and we compare it with the one available on PETSc (version 3.2, compiled with OpenMPI). The calculations performed by both implementations are identical. The figure depicts the relative speed-up obtained after measuring the execution time to perform 4000 Jacobi preconditioned Richardson iterations. The initial approximation of the solution is, in both cases, zero. The system used is equipped with the Intel Xeon E5-2670 with 32 GB of RAM and QDR Infiniband.
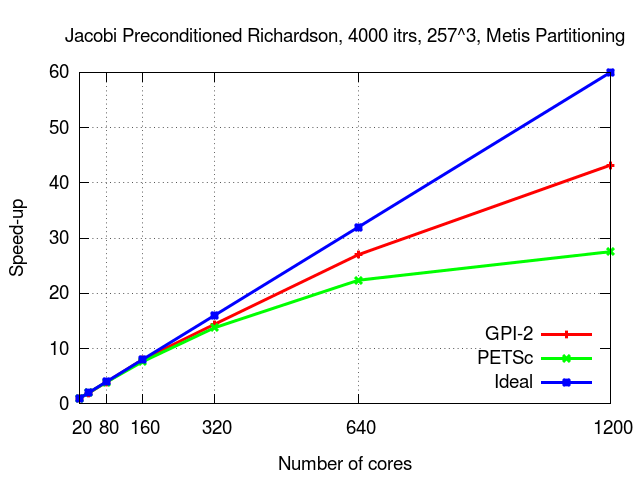
The following are results on a more recent system: Intel Xeon E5-2680v2 (Ivybridge) with FDR Infiniband.
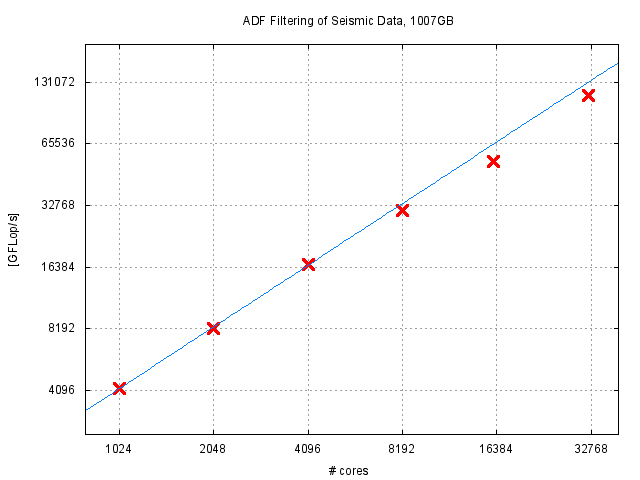
Seismic
GPI is one of the main building blocks of many applications at the Fraunhofer ITWM particularly in the seismic area. One example of such applications is the Parallel Edge- and Coherence-Enhancing Anisotropic Diffusion Filter (Parallel ECED). This filter is
used to reduce the noise of seismic data while preserving its layer structure at the same time. These are some results on up to 32768 cores.
Another is Pre-Stack Pro, the first product of Sharp Reflections, a spin-off of Fraunhofer ITWM and EnVision AS.

Visualisation
When it comes to visualization (Real-Time Ray-Tracing, Photo-realistic Rendering), GPI is used to deliver parallel performance as in the example shown below.
