Right on time for ISC’14, a new version of GPI-2 (v1.1.0) is released.
The new version includes the following new features:
- Non-blocking collectives
- Threads integration
- Integrated MPI Interoperability
- Asynchronous topology building
- Focus on large scale execution
- GPU (CUDA) integration
- Load Leveler support
In this post, we go through some of these new features, why we think they are important and some results obtained so far.
Non-blocking collectives
One of the most important facts in GPI-2 is the ability to overlap communication and computation. To this end, it is important to have non-blocking operations, which allow us to trigger communication and return to useful work. The new version of GPI-2 adds this support for non-blocking collectives through the timeout mechanism present in all non-local operations. This allows an application to trigger the collective operation and immediately return to useful work.
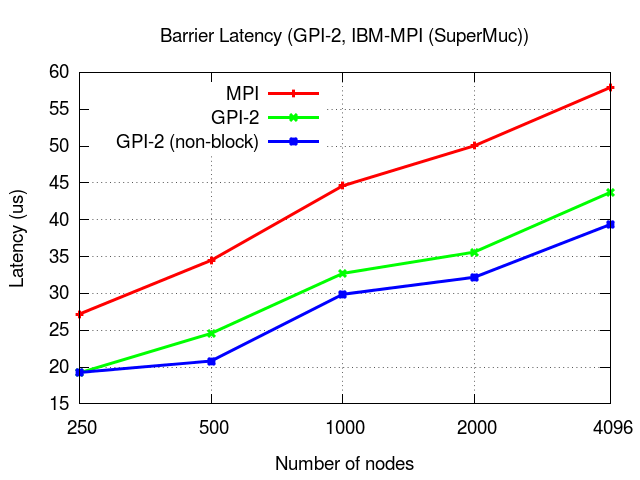
Below we show the case of the collective operation gaspi_barrier, up to 4096 nodes.
GPU (CUDA) integration
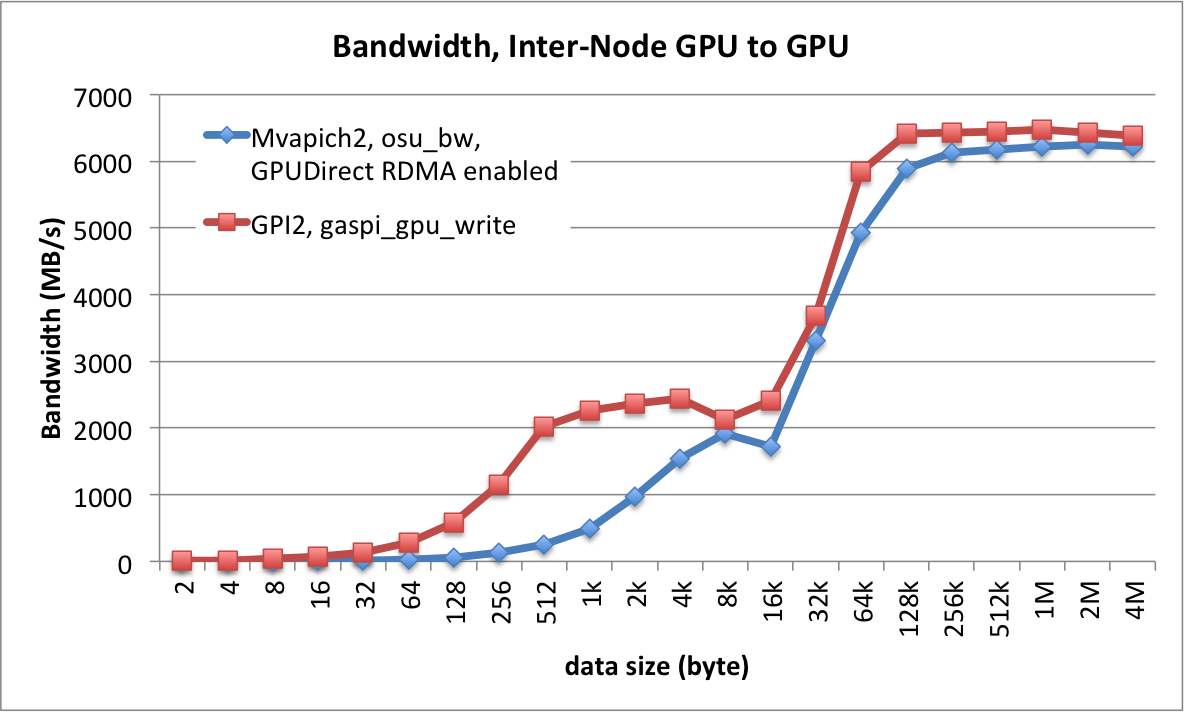
The support for GPUs was not yet integrated in the release version of GPI-2 and was one of our goals for this next release. This is now the case. Below is depicted the obtained bandwidth between GPUs when using GPI-2.
Threads integration
The GPI-2 programming model envisions the use of threads (instead of processes) within a node. Not only GPI-2 is thread-safe but also due to the increasing number of nodes and the need for more task-based approaches and finer-grained parallelism. In that spirit, the new version of GPI-2 includes a small threading package (gaspi_threads), integrated in the GPI-2. As before, the use of other thread approaches (OpenMP, Cilk, etc.) continues to be supported.
MPI Interoperability
Large parallel applications, developed over several years, often reach several thousands or even millions of lines of code. Moreover, there is a large set of available libraries and tools which run with MPI. The task to modify a large application and experiment with a new programming model is thus challenging, requires a large effort and is too often regarded as low priority.
With this in mind, GPI-2 cooperates now better with MPI and both can be used simultaneously. This allows an incremental porting of a large application, the usage of existing MPI libraries and infrastructure. A user can keep its batch system scripts to start the MPI application and all the surrounding infrastructure but still experiment with GPI-2 and slowly introduce it, concentrating for example on the communication routines.
Large scale execution
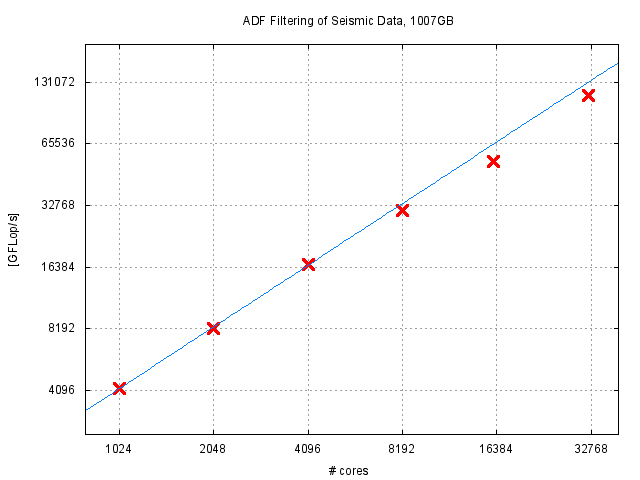
On the road to Exascale, large scale execution is now a primary target on the further development of GPI-2. By large scale execution, we mean thousands of nodes with hundreds of thousand cores. Above, we already showed some results with the non-blocking collectives up to 4096 nodes, with a total of 65536 cores. Below we show some results on a real application from the seismic imaging area where we scale up to 32768 cores. This is the first version of GPI-2 that was tested and executed on such a setting.
The GPI-2 team hopes that these features provide a good motivator to try GPI-2. So go ahead to the Download page and give a try to the new version.
Recent Comments